AsterixDB is a Scalable, Open Source BDMS(Big Data Management System). 最重要的两个特点就是分布式和NoSQL存储,主要的科研工作也围绕在这两个方面。
ADM: Modeling Semistructed Data in AsterixDB
Dataverses, Datatypes, and Datasets
database a place to create and manage the types, datasets, functions and other artifacts.
datatype tells AsterixDB what you know a priori about one of the kinds of data instances that you want AsterixDB to hold for you.
dataset a collection of data instances of a datatype
open datatype
Instances of open datatypes are permitted to have additional content, beyond what the datatype says, as long as they at least contain the information prescribed by the datatype definition.
Datatypes are open by default unless you tell AsterixDB otherwise.
Open datatype brings storage overhead because asterixDB needs to store repeatedly in the individual data instances that you give it. (Individual could have parts in common which should be declared in the open datatype)
1 | DROP DATAVERSE TinySocial IF EXISTS; |
Create Datasets and Indexes
1 | USE TinySocial; |
Querying the Metadata Dataverse
1 | /* returns the entire object from the metadata dataset containing the descriptions of all datasets */ |
Sql++ supports a SELECT VALUE which returns an entire object instead of a single value.
Loading Data Into AsterixDB
Using JSON format data
1 | USE TinySocial; |
Architecture
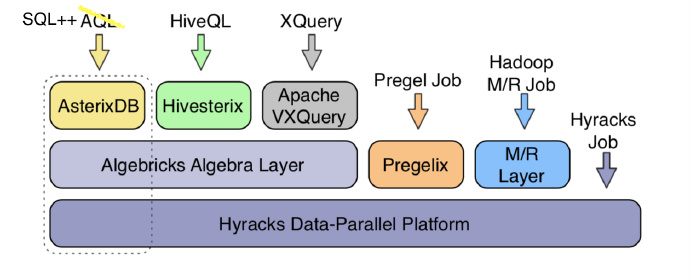
Hyracks
Hyracks is the runtime layer (executor) whose responsibility is to accept and manage data-parallel computations
Jobs are submitted to Hyracks in the form of DAGs made up of Operators and Connectors.
Operators consuming partitions of their inputs and producing output partitions.
Connectors redistribute data from the output partitions and provide input partitions for the next Operator.
Algebricks
It is layer above hyracks which used to optimize the query plan.
To process a query, asterixDB compiles an AQL query into an Algebricks algebraic program. This program is then optimized via algrebraic rewrite rules that reorder the Algebricks Operator and intoduce partitioned parallelism for scalable execution.
Storage and Indexing
AsterixDB has Log-Structured-Merge(LSM) trees as the underlying technology for all its internal data storage and indexing. In LSM, the state of the index is stored in different components with different lifecycles.
Entries being inserted are inserted into an LSM-tree are placed into a component that resides in main memory —— in-memory component . When the memory occupancy of the in-memory component exceeds a threshold, the entries will be flushed into a component of the index that resides on disk — a disk component.